Citation-grade verification: the missing fifth stage of AI research
Contents
TL;DR. AI research tooling has specialized into five stages. Stages 1–4 (discovery, paper extraction, evidence synthesis, retrieval) help researchers find, read, and digest published work. Stage 5 — verifying the specific statement a writer is about to commit to in print — has been missing. That's where citation-grade defensibility lives, and where the citable error usually enters. Lenz fills that stage.
The five stages of an AI research workflow
AI research tooling now sits in five distinct stages. Each has its own tools, its own output artifact, and its own job.
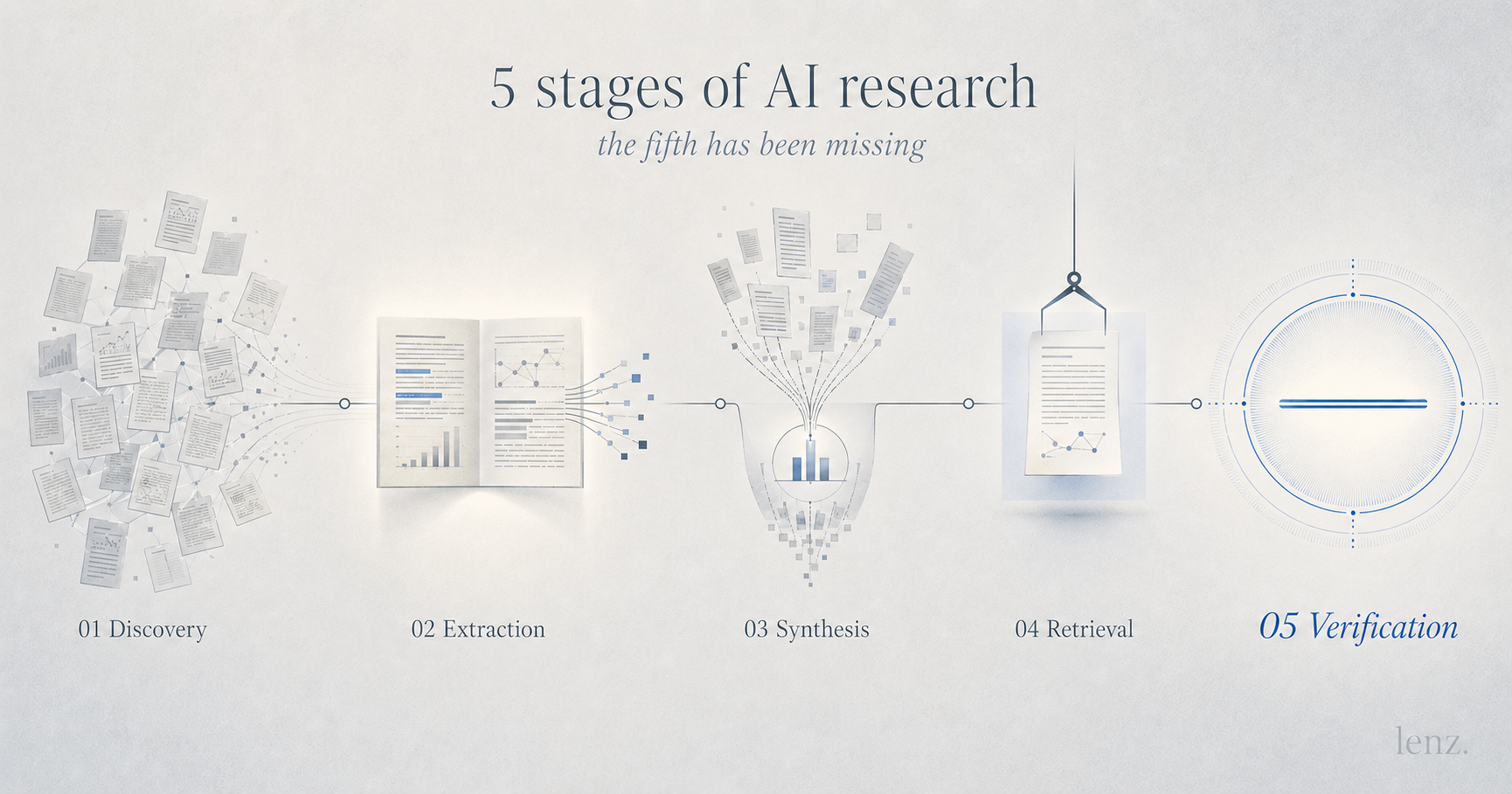
- Stage 1 — Discovery. What papers exist on this topic? Semantic Scholar, R Discovery, ResearchRabbit, Connected Papers, Litmaps, Inciteful. Output: a candidate set of papers worth reading.
- Stage 2 — Paper understanding and extraction. What does this paper actually say? SciSpace, Elicit, Paperpal, Paperguide. Output: structured findings, summaries, extractable data from individual papers.
- Stage 3 — Evidence synthesis and answering. What does the field think? Consensus, Scite, Atlas, Perplexity. Output: aggregated stance across a body of work.
- Stage 4 — Retrieval and access. Can I get full text on these papers? Sourcely. Output: the actual papers you need to read.
- Stage 5 — Statement verification. Is the specific sentence I'm about to commit to in writing actually true? Lenz. Output: a verdict, an argument trace, and a citable per-statement URL.
The first four stages map onto behaviors researchers already perform. Stage 5 maps onto the moment they're most exposed — the sentence they're putting their name on — and historically, no tool has been built for it.
The gap — where citation-grade defensibility lives
When a researcher writes a sentence they intend to publish, that sentence is the unit of their liability. It's what they'll be quoted on. It's what the editor will challenge. It's what a critic will pick apart.
The first four stages of the workflow help with everything except that final sentence. Discovery surfaces papers. Extraction summarizes them. Synthesis maps field stance. Retrieval gets you full text. None of these check whether the specific sentence you're committing to in print actually holds.
That gap — between the synthesis the existing tools produce and the statement the writer commits to — is where citation-grade defensibility lives. Fill it well and the citation stands up under scrutiny. Skip it and the citable error enters.
How statement verification fits the existing workflow
Lenz isn't a different version of Consensus, Scite, or Elicit. It's the step that comes after them.
The integrated workflow looks roughly like this:
- Discovery and extraction — use ResearchRabbit, Semantic Scholar, or Litmaps to find candidate papers; use SciSpace, Elicit, or Paperpal to read and extract findings.
- Synthesis — use Consensus or Scite to map field stance and citation context across the literature.
- Retrieval — use Sourcely to get full text where needed.
- Drafting — write the sentence you're going to commit to in print, with the qualifiers that match what the evidence actually supports.
- Statement verification — feed the drafted sentence to Lenz. Read the argument trace. Check the verdict against your draft. Adjust if the evidence supports a narrower or stronger claim than you wrote.

Step 5 is the step most workflows skip — historically left to the writer's own care and the editor's red pen. Both useful, both fallible at scale. Closing that gap with a structured verification surface is what statement verification tooling is for.
The existing tools aren't being replaced. They're being completed.
What citation-grade verification looks like in practice
Two examples, both running on Lenz:
Peer review guarantees the accuracy of a published study's findings.False
Verdict: False. The argument trace surfaces evidence from the replication-crisis literature: peer-reviewed findings frequently fail to replicate; peer review checks methodology and clarity, not factual accuracy.
Verdict: Mostly True (7/10 confidence). The argument trace flags a construct-conflation issue: the evidence more precisely supports analytic thinking style and critical-thinking dispositions than general intelligence. The popular phrasing overstates the precise finding.
The verdict label is the headline. The argument trace is the actual product — the work the writer can defend their citation against.
Why AI research needs a fifth stage
AI research has four established stages. There should be five.
The fifth stage — citation-grade verification of the specific statement you're committing to — is where the citable error usually enters, and where defensibility actually gets built.
Lenz fills that stage. The other tools in the stack keep doing their jobs.
Want to see what statement verification looks like on a sentence from your own writing? Verify a statement — any sentence in, verdict + argument trace out.
The library at lenz.io/library holds the corpus of statements already verified.
Verifications referenced in this post reflect Lenz's analysis at the time of publishing; verdicts can update as evidence accumulates, and the live pages with statements always show the current state. Tool descriptions reflect publicly available information about each product as of April 2026.