Three claims, three verdicts, one process
Contents
- What statement verification looks like across health, current events, and science.
- Why domain-agnosticism is the point
- Three examples from the Lenz corpus, deliberately picked from three different domains, to show what that looks like in practice.
- What three verifications across three domains tell us
What statement verification looks like across health, current events, and science.
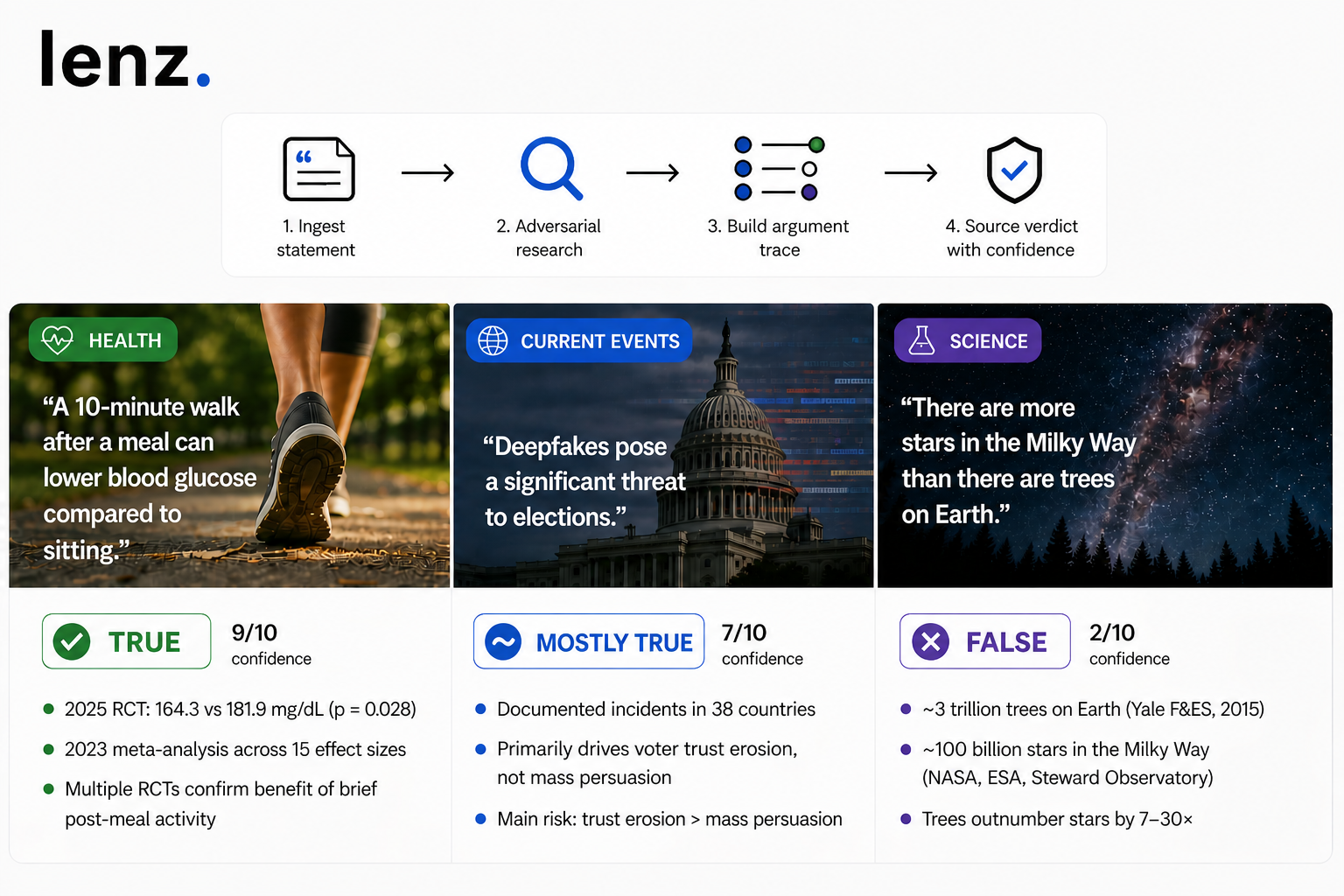
TL;DR. Statement verification is a process, not a topic. The same Lenz workflow handles a wellness claim, a political statement from a viral story, and a popular science meme — and produces different verdicts because the evidence differs, not because the process does. This piece walks through three real verifications and what each one revealed.
Why domain-agnosticism is the point
Most AI research tools are scoped to a domain. Consensus, Scite, and Elicit operate on the academic-paper layer. They're built for the literature, and they do that job well. Outside the literature — political statements in the news cycle, health advice circulating on Instagram, a science meme going around social — those tools don't apply.
But the writer's liability isn't scoped to academia. When a researcher cites a study, a journalist quotes a politician, or a content creator shares a viral fact, the unit they're putting their name on is the same shape: a discrete sentence that has to hold up to scrutiny. Citation-grade defensibility is domain-agnostic by definition, because the writer's accountability is.
That means the verification surface has to be domain-agnostic too. Same process — adversarial pipeline, sourced verdict, argument trace — applied wherever the sentence comes from.
Three examples from the Lenz corpus, deliberately picked from three different domains, to show what that looks like in practice.
Verdict: True (9/10 confidence)
A common wellness claim picked up everywhere from medical Twitter to general-health newsletters. The claim is specific — 10 minutes, post-meal, blood glucose vs. sedentary control — which is exactly the level of precision verification works on.
What the argument trace surfaced:
- A 2025 RCT measured peak post-meal glucose at 164.3 mg/dL after a 10-minute walk versus 181.9 mg/dL with sedentary control (p = 0.028).
- A 2023 meta-analysis across 15 effect sizes confirmed the pattern, with optimal timing in the first 0–29 minutes after eating.
- Multiple additional RCTs confirm that even brief light activity (5–10 minutes) immediately post-meal improves glycemic response.
The trace flagged scope-refining caveats — the 2025 trial used a glucose drink rather than a mixed meal; one cycling study found no benefit when activity began 15 minutes post-baseline; type-1 diabetics on closed-loop systems showed better results with pre-meal walking. None undermine the core claim; they refine its scope.
What this verification reveals about the process: when independent high-quality studies converge and the popular phrasing matches what those studies actually measured, the verdict lands cleanly True. No equivocation needed.
Verdict: Mostly True (7/10, 8/10 confidence)
A claim circulating widely as AI capabilities have improved — picked up by journalists, policy commentators, and tech writers warning about election integrity. The claim asserts a specific direction and a specific magnitude: deepfakes pose a significant threat.
What the argument trace surfaced:
- Real, documented incidents — AI-generated robocalls suppressing voter turnout, fabricated political advertisements — across 38 countries (Brookings, Brennan Center, legislative testimony).
- The 2024–2025 global "super election cycle," covering nearly half the world's population, did not produce the catastrophic "deepfake election" many experts had predicted.
- Controlled experiments found deepfake videos have "minimal effects" on direct voter persuasion. The demonstrated danger centers on trust erosion and procedural disinformation rather than mass persuasion.
- The "liar's dividend" is real — awareness of deepfakes can be weaponized to dismiss authentic footage, creating its own distinct harm.
What this verification reveals about the process: a Mostly True verdict often takes the shape "the claim is directionally correct, but the magnitude is unproven." The verification doesn't dispute that deepfakes threaten elections — they do. It refines what kind of threat (trust erosion > mass persuasion) and how severe (real but smaller than warned). A writer citing the claim verbatim risks the magnitude critique; citing it with the magnitude caveat doesn't.
There are more stars in the Milky Way galaxy than there are trees on Earth.False
Verdict: False (2/10 confidence)
A claim that goes viral on social periodically, often dressed up as a counterintuitive fact about scale. It feels true — the universe is unimaginably big, the Milky Way is a galaxy, of course there are more stars than there could be trees on one planet.
What the argument trace surfaced:
- Yale School of Forestry & Environmental Studies (2015) estimates ~3 trillion trees on Earth.
- NASA, ESA, and Steward Observatory estimate ~100 billion stars in the Milky Way (BBC Science Focus puts the range at 100–400 billion).
- The actual ratio: Earth's trees outnumber the Milky Way's stars by a factor of 7–30×.
The trace flagged a logical fallacy that props up the popular version — inferring "trillions of stars" from galactic mass estimates (up to 3 trillion solar masses). That's a non sequitur: galactic mass includes dark matter, gas, and dust, not just stars.
What this verification reveals about the process: a False verdict here isn't about origin or framing — it's factual inversion. The popular claim has the relative magnitudes reversed. The verification surfaces this not by proving the universe small, but by independently bounding both quantities and observing that the magnitudes go the other way.
What three verifications across three domains tell us
The verdicts diverged because the evidence diverged.
What the three verdicts have in common is that the verification process makes its work visible. A True verdict on the walking claim isn't an authority assertion — it's the trace of the studies that converged on the answer. A Mostly True verdict on the deepfake claim isn't a hedge — it's the gap between the real direction of evidence and the unproven magnitude. A False verdict on the stars-vs-trees claim isn't snobbery about science — it's the independent magnitude estimates that go in the opposite direction from the popular phrasing.
Three different verdict mechanics:
- Convergent evidence (Claim 1) — when independent high-quality sources agree on the answer
- Magnitude question (Claim 2) — when the claim is directionally correct but the predicted scale or severity isn't supported
- Factual inversion (Claim 3) — when the popular claim has the underlying relationship reversed
If you want to test what statement verification looks like on a sentence from your own writing, verify a statement — any sentence in, verdict + argument trace out. The library at lenz.io/library holds the corpus of statements already verified.
Verifications referenced in this post reflect Lenz's analysis at the time of publishing; verdicts can update as evidence accumulates, and the live claims pages always show the current state. Health-related and current-events examples are illustrations of citation methodology, not medical advice or political endorsement. Tool descriptions reflect publicly available information about each product as of April 2026.